이커머스에서 상품 조회 캐시 전략 선택하기 — 키 설계부터 읽기/쓰기/무효화 전략까지

TL;DR
- 데이터 특성(변경 빈도, 무효화 복잡도)에 따라 TTL과 무효화 전략을 다르게 가져갔다.
- 인덱스 방향 최적화 + 캐시 적용으로 p99 1.08s → 74ms(93% 개선), RPS 113 → 153(35% 향상).
들어가면서
이커머스 프로젝트를 하면서 상품 목록 조회, 상품 상세 조회 등 읽기 성능 개선이 필요해졌다. 막상 캐시를 적용하려니 고민이 생겼다.
“어떤 데이터를 캐시할까? 캐시 키 이름은? 데이터가 바뀌면 캐시는 어떻게?”
이번 글에서는 SLO 기준을 정하고, 테스트 데이터를 만든 뒤, 캐시를 적용하면서 고민했던 과정을 정리해봤다. 특히 캐시 전략을 선택할 때 어떤 기준으로 판단했는지에 집중했다.
캐시 전략 개요
읽기 전략, 쓰기 전략, 무효화 전략 세 가지를 조합해서 결정해야 한다.
읽기 전략
| 전략 | 동작 방식 | 고려할 점 |
|---|---|---|
| Cache-Aside | 앱이 캐시 확인 → miss면 DB 조회 → 캐시 저장 | 구현이 단순, 읽기 많은 워크로드에 적합 |
| Read-Through | 캐시가 DB 조회 대행 | 캐시 인프라 의존도 높음 |
| Refresh-Ahead | TTL 만료 전 백그라운드 갱신 | 핫 데이터에 유리, 구현 복잡도 증가 |
쓰기 전략
| 전략 | 동작 방식 | 고려할 점 |
|---|---|---|
| Write-Through | DB + 캐시 동시 저장 | 일관성 보장, 쓰기 지연 증가 |
| Write-Behind | 캐시만 저장 → 나중에 DB 반영 | 쓰기 성능 최고, 데이터 유실 위험 |
| Write-Around | DB만 저장, 캐시 무시 | 캐시 오염 방지, 다음 읽기 시 miss |
무효화 전략
| 전략 | 동작 방식 | 고려할 점 |
|---|---|---|
| TTL Only | 시간 지나면 자동 만료 | 구현 단순, 지연 허용 시 적합 |
| Evict | 변경 시 캐시 삭제 → 다음 요청이 DB 조회 | 구현 단순, 동시성 안전 |
| Update | 변경 시 캐시 덮어쓰기 | miss 없이 즉시 반영, 동시성 문제 주의 |
이번에 브랜드 조회, 상품 상세/목록 조회에 캐시를 적용하면서 이 세 가지 전략을 조합해 선택했다.
테스트 환경
성능 측정을 위한 테스트 데이터를 준비했다.
데이터 규모
| 항목 | 값 | 설계 근거 |
|---|---|---|
| 상품 | 50만 건 | 대용량 조회 시 인덱스 유무 차이를 명확히 측정 |
| 브랜드 | 10개 (각 5만 건) | 균등 분배로 동일 조건에서 비교 가능 |
| 좋아요 | 약 565만 건 | 핫키 분포로 정렬 인덱스 효과 측정 |
| 유저 | 1만 명 | - |
| 주문 | 5만 건 | 유저당 평균 5개 |
좋아요 분포: 극단적 쏠림
| 구간 | 상품 수 | 좋아요 수 | 비율 |
|---|---|---|---|
| 상위 1% | 5천 개 | 각 1천 개 → 500만 개 | 88% |
| 상위 1~10% | 4.5만 개 | 각 10개 → 45만 개 | 8% |
| 상위 10~30% | 10만 개 | 각 2개 → 20만 개 | 4% |
| 하위 70% | 35만 개 | 0개 | 0% |
실제 서비스에서 인기 상품에 좋아요가 몰리는 현상을 재현하고 싶었다. 상위 1%가 전체 좋아요의 88%를 차지하는 극단적 핫키 분포다.
SLO 기준
| 지표 | 목표 |
|---|---|
| p99 응답 시간 | 300ms 이내 |
| RPS | 100 이상 |
| 에러율 | 1% 미만 |
이 중 p99와 RPS를 핵심 지표로 봤다.
- p99: 평균이 빨라도 일부 요청이 느리면 사용자 경험이 나빠진다.
- RPS: 처리량이 낮으면 트래픽 증가 시 병목이 된다.
상품/브랜드별 캐시 전략 선택과 이유
브랜드 단건
브랜드 정보는 거의 변하지 않다고 판단하여 TTL을 1일로 길게 잡고, 변경 시에만 캐시를 삭제하는 방식을 선택했다.
- 읽기 (Cache-Aside): 캐시 miss 시 DB 조회 후 캐시에 저장한다.
- 쓰기 (Write-Around): DB만 저장한다. 비동기적으로 DB에 저장하거나, DB와 캐시에 동시에 저장할 정도로 일관성이 중요하지 않다고 판단했다.
- 무효화 (Evict + TTL): 변경 시 캐시를 삭제하고, TTL은 1일로 길게 잡았다. 변경이 적으니 히트율을 최대화할 수 있다.
- 키:
brand:v1:{id}— 버전을 포함해서 스키마 변경 시 대응할 수 있게 했다. - 캐시 레이어: Repository에서 캐싱한다. 브랜드는 여러 상품에서 참조되므로 재사용성이 높다.
상품 단건
상품은 브랜드보다 민감하다. 재고와 가격이 포함되어 있어서 변경이 많은 데이터다.
- 읽기 (Cache-Aside): 캐시 miss 시 DB 조회 후 캐시에 저장한다. 재고라는 중요한 데이터를 갖고 있어서 캐시 인프라 의존도를 낮추고, miss 시 DB에서 정확한 값을 가져오는 방식을 택했다.
- 쓰기 (Write-Around): DB만 저장한다. 브랜드와 마찬가지로 비동기 저장이나 동시 저장이 필요할 만큼 일관성이 중요하지 않다고 판단했다.
- 무효화 (Evict + TTL): 변경 시 캐시를 삭제하고, 변경이 많을 것으로 판단해 브랜드보다 훨씬 짧은 TTL 5분을 사용했다.
- 키:
product:v1:{id}— 버전을 포함해서 스키마 변경 시 대응할 수 있게 했다. - 캐시 레이어: Repository에서 캐싱한다. 상품 상세, 목록 등 여러 곳에서 참조되므로 재사용성이 높다.
상품 목록
목록 캐시가 가장 까다로웠다. 조건 조합이 폭발하기 때문이다.
- 읽기 (Cache-Aside): 캐시 miss 시 DB 조회 후 캐시에 저장한다.
- 무효화 (TTL Only): Evict 대신 TTL Only를 선택했다. 상품 하나가 변경되면 상품 상세, 브랜드 목록, 전체 목록 등 여러 캐시를 삭제해야 하는데, 재고 변경이 빈번하면 히트율이 급락한다. 그래서 명시적 무효화 없이 1분 TTL로 자연 갱신되게 했다.
- 키:
product:list:v1:{sortType}:{brandId}product:list: 네임스페이스. 역할별로 분리해서 충돌 방지.v1: 버전. 스키마 변경 시 과거 캐시와 강제 분리.{sortType}: 정렬 타입 (latest,likes_desc).{brandId}: 브랜드 필터가 있으면 해당 값, 없으면 null.- 조건 조합이 많아서 전부 캐시하면 무효화가 복잡해지므로, 비회원 + 첫 페이지 + 최신순/인기순만 캐시한다.
- 캐시 레이어: Facade에서 캐싱한다. 목록은 여러 조건이 조합된 결과이므로 Repository보다 상위 레이어에서 처리한다.
적용된 캐시 전략 요약
| 대상 | 읽기 | 쓰기 | 무효화 | TTL | 키 | 캐시 레이어 |
|---|---|---|---|---|---|---|
| 브랜드 | Cache-Aside | Write-Around | Evict | 1일 | brand:v1:{id} | Repository |
| 상품 단건 | Cache-Aside | Write-Around | Evict | 5분 | product:v1:{id} | Repository |
| 상품 목록 | Cache-Aside | - | TTL Only | 1분 | product:list:v1:{sortType}:{brandId} | Facade |
고려했지만 적용하지 않은 것
TTL Only를 쓰면 캐시 스탬피드 문제가 생길 수 있다. 만료 시점에 요청이 몰리면서 DB 중복 조회와 캐시 중복 쓰기가 발생한다. 선계산 (Early Recompute)이나 TTL 지터(TTL Jitter) 같은 해결책이 있지만, 지금은 불필요하다고 판단해 적용하지 않았다.
인덱스 최적화 시행착오
캐시 적용 전에 인덱스 최적화를 먼저 시도했다.
인덱스를 적용했더니 오히려 p99가 느려졌다.
| 단계 | p99 | avg | RPS |
|---|---|---|---|
| 미적용 | 1.32s | 463ms | 103 |
| 인덱스 적용 (ASC) | 1.41s | 362ms | 111 |
avg는 22% 개선됐지만, p99는 7% 악화됐다.
정확한 원인은 단정짓기 어렵지만, 처리량 증가로 인한 리소스 경합으로 추정했다. 쿼리가 빨라지면서 RPS가 8% 올랐고, 동시 요청이 늘어나 DB 커넥션 경합이 증가했을 가능성이 있다.
인덱스 방향 변경
EXPLAIN을 확인해보니 Backward index scan이 발생하고 있었다. 쿼리는 ORDER BY like_count DESC인데 인덱스는 ASC로 생성되어 있었다.
1
2
3
4
5
// 기존 (ASC)
@Index(name = "idx_product_like_count", columnList = "like_count")
// 변경 (DESC)
@Index(name = "idx_product_like_count", columnList = "like_count DESC")
Backward index scan의 오버헤드가 얼마 쿼리 정렬 방향과 인덱스 방향을 일치시켜봤다.
인덱스 방향 변경 결과
| 지표 | ASC | DESC | 개선율 |
|---|---|---|---|
| p99 | 1.08s | 586ms | -46% |
| avg | 342ms | 173ms | -49% |
| RPS | 113 | 131 | +16% |
p99가 46% 개선됐다.
| API | ASC | DESC | 변화 |
|---|---|---|---|
| 브랜드필터 | 57% | 99% | +42%p |
| 가격순 | 75% | 99% | +24%p |
| 좋아요목록 | 83% | 99% | +16%p |
| 주문목록 | 83% | 99% | +16%p |
| 최신순 | 39% | 60% | +21%p |
| 인기순 | 38% | 59% | +21%p |
브랜드필터, 가격순, 좋아요목록, 주문목록은 99% 성공률을 달성했다. 하지만 최신순과 인기순은 60% 수준에 머물렀다.
인덱스만으로는 한계가 있었다
인덱스 방향 최적화로 상당한 개선이 있었지만, 전체 목록 정렬(최신순/인기순)은 여전히 SLO를 달성하지 못했다.
인덱스로 개별 쿼리 속도는 빨라졌지만, RPS가 늘면서 대기하는 요청도 늘어났다. 결국 DB 조회 자체를 줄이는 캐시 적용이 필요했다.
성능 개선 결과
전체 비교
| 단계 | p99 | avg | RPS |
|---|---|---|---|
| 인덱스 (ASC) | 1.08s | 342ms | 113 |
| 인덱스 (DESC) | 586ms | 173ms | 131 |
| 인덱스 (DESC) + 캐시 | 74ms | 10ms | 153 |
단계별 개선율
| 비교 | p99 | avg | RPS |
|---|---|---|---|
| ASC → DESC | -46% | -49% | +16% |
| DESC → DESC + 캐시 | -87% | -94% | +17% |
| ASC → DESC + 캐시 | -93% | -97% | +35% |
API별 성공률 (p99 < 300ms)
| API | 인덱스만 (DESC) | 캐시 적용 후 |
|---|---|---|
| 최신순 | 60% | 99% |
| 인기순 | 59% | 100% |
| 브랜드필터 | 99% | 100% |
| 가격순 | 99% | 100% |
| 좋아요목록 | 99% | 100% |
| 주문목록 | 99% | 100% |
인덱스 방향 최적화만으로 일부 API는 99%를 달성했지만, 최신순/인기순은 60% 수준이었다. 캐시를 추가하자 전체 API가 99% 이상을 달성했다.
끝으로
캐시 전략에는 정답이 없어서, 나만의 기준을 찾는 게 어려웠다. 이번에 데이터 특성에 따라 읽기, 쓰기, 무효화 전략의 트레이드오프를 비교하는 연습을 해봤다.
이번에 캐시 전략을 선택하면서 세 가지 기준을 세웠다.
첫 번째, 읽기/쓰기 비율을 봤다. 자주 읽히고 덜 업데이트되는 데이터가 캐싱하기 좋다. 브랜드, 상품, 목록 모두 읽기가 압도적으로 많아서 캐싱 대상으로 적합하다고 판단했다.
두 번째, 무효화 복잡도를 봤다. 단건 조회는 데이터가 바뀌면 해당 키 하나만 삭제하면 된다. 반면 목록은 상품 하나가 바뀌면 전체 목록, 정렬별 목록 등 여러 캐시를 삭제해야 한다. 단건은 무효화가 단순하니 Evict로 즉시 삭제했다. 목록은 무효화가 복잡하고, 최신성보다 빠른 조회가 더 중요하다고 판단해서 명시적 무효화 없이 짧은 TTL로 자연 갱신되게 했다.
세 번째, 트래픽 집중도를 봤다. 목록의 경우 모든 정렬/필터 조합을 캐시하면 메모리 낭비고 히트율도 낮다. 가장 많이 호출되는 조합(최신순, 인기순)만 선별해서 캐시했다.
| 대상 | 읽기 | 쓰기 | 무효화 복잡도 | 읽기 전략 | 쓰기 전략 | 무효화 전략 | 비고 |
|---|---|---|---|---|---|---|---|
| 브랜드 | ↑ | ↓ | 단순 | Cache-Aside | Write-Around | Evict + TTL 1일 | 변경 거의 없음 |
| 상품 단건 | ↑ | ↓ | 단순 | Cache-Aside | Write-Around | Evict + TTL 5분 | 재고/가격 변경 있음 |
| 상품 목록 | ↑ | ↓ | 복잡 | Cache-Aside | - | TTL Only 1분 | 최신순/인기순만 캐시 |
실무에서도 병원 통계 AI 분석 결과, 혈압 분석 결과 등 캐싱할 데이터가 늘어나고 있다. 이번 고민을 바탕으로 기존 캐시 전략도 점검하고, 새로운 대상에도 적절한 전략을 세워봐야겠다.
부록: 캐시 구현 구조
아키텍처
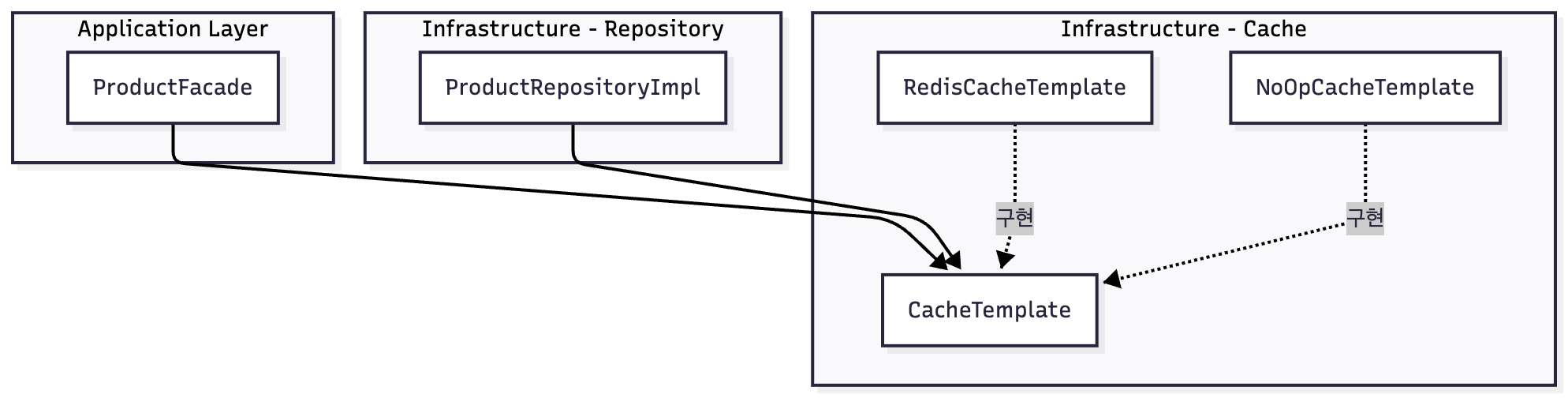
Application 계층은 CacheTemplate 인터페이스에만 의존한다. 프로덕션에서는 RedisCacheTemplate, 테스트에서는 동작 없는 NoOpCacheTemplate을 주입한다.
1
2
3
4
5
6
public interface CacheTemplate {
<T> Optional<T> get(CacheKey<T> cacheKey);
<T> void put(CacheKey<T> cacheKey, T value);
void evict(CacheKey<?> cacheKey);
<T> T getOrLoad(CacheKey<T> cacheKey, Supplier<T> loader);
}
getOrLoad 패턴
캐시 조회의 핵심은 getOrLoad() 메서드다. 캐시에 있으면 바로 반환하고, 없으면 Supplier를 실행해서 DB에서 조회한 뒤 캐시에 저장한다.
1
2
3
4
5
6
7
8
9
10
11
12
public <T> T getOrLoad(CacheKey<T> cacheKey, Supplier<T> loader) {
Optional<T> cached = get(cacheKey);
if (cached.isPresent()) {
return cached.get();
}
T value = loader.get();
if (value != null) {
put(cacheKey, value);
}
return value;
}
Supplier<T>를 사용해서 캐시 미스 시에만 DB 조회가 실행된다.
CachePolicy로 TTL/키 중앙 관리
TTL과 키 생성 규칙이 코드 곳곳에 흩어지면 관리가 어렵다. CachePolicy enum으로 중앙 관리했다.
1
2
3
4
5
6
7
8
9
10
public enum CachePolicy {
PRODUCT("product", Duration.ofMinutes(5)),
BRAND("brand", Duration.ofHours(6)),
PRODUCT_LIST("product:list", Duration.ofMinutes(1));
public String buildKey(Long id) {
return prefix + ":" + VERSION + ":" + id;
// → "product:v1:123"
}
}
캐시 구현 포인트 정리
| 포인트 | 적용 내용 |
|---|---|
| DIP | CacheTemplate 인터페이스로 Redis 의존성 역전 |
| Supplier | 캐시 미스 시에만 DB 조회 (지연 실행) |
| CachePolicy | TTL/키 전략을 Enum으로 중앙 관리 |
| 테스트 격리 | NoOpCacheTemplate으로 캐시 없이 테스트 |