루퍼스 2주차 WIL — 설계 의사결정과 문서화

루퍼스 2주차 WIL
이번 주 핵심 인사이트
설계는 점진적 진화다 - 고도화보다 동작하는 코드 우선
- “처음부터 고도화를 생각하지 말고, 조금씩 조각을 한다고 생각하라”
- 동작하는 코드를 먼저 만들고 점진적으로 개선하는 것이 완벽한 초기 설계보다 실용적
기술적 결정의 “왜”를 설명할 수 있어야 한다
주문-결제 API 분리를 고려한다면?
- 고객 경험: 결제 실패 시 다른 결제수단으로 재시도 가능
- 트랜잭션 제어: 주문 생성과 결제 처리를 독립적으로 관리
- 에러 처리: 결제 실패해도 주문은 유지되어 복구 용이
OrderItem을 Entity로 선택한다면?
- 가까운 미래 요구사항 대응: 부분 반품, 개별 배송 추적
- 독립된 상태 관리: 개별 아이템별 상태 변화 추적
- 느슨한 결합: OrderItem 변경이 Order에 영향 없음
좋아요 API를 멱등하게 설계한다면?
- 동시성 안정성: 같은 요청 반복 시에도 일관된 결과
- 사용자 경험: 네트워크 불안정 상황에서도 안전한 재시도
설계 문서는 커뮤니케이션 도구다
- 읽는 사람 입장에서 생각: “글쓰기처럼 보는 사람을 고려하는 게 설계의 핵심”
- 의사결정 기록: “왜 그 시점에 그런 결정을 했는지” 남기기 (ADR)
- 목적: 미래의 협업자가 맥락을 이해하고 더 나은 결정을 내릴 수 있도록 하기 위한 문서
2주차 핵심 학습 내용
1. 도메인 설계 철학
Entity vs Value Object 선택 기준
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 초기 판단 - 식별자 불필요하니 VO
@Embeddable
class OrderItem {
private Long productId;
private int quantity;
private BigDecimal price;
}
// 재판단 - 확장성 고려해 Entity
@Entity
class OrderItem {
@Id
private Long id; // 개별 추적 가능
@ManyToOne
private Order order;
private Long productId;
private int quantity;
private BigDecimal price;
private String status; // 상태 관리 가능 (배송중, 반품 등)
}
판단 기준
| 기준 | Entity 선택 | VO 선택 |
|---|---|---|
| 식별자 | 독립 조회/추적 필요 | 부모에 종속 |
| 생명주기 | 독립적 상태 변화 | 부모와 동일 |
| 비즈니스 로직 | 개별 상태 관리 필요 | 단순 데이터 묶음 |
| 확장성 | 부분 반품, 개별 추적 | 단순 조회만 |
학습 과정
- 초기 판단: 일부만 보고 애매하게 느낌 (식별자만 고려)
- 학습 후: 세부적인 차이 확인 (생명주기, 비즈니스 로직, 확장성)
- 결과: 선택 기준이 명확해짐 - 확장 가능성 고려 시 Entity가 적절
핵심 깨달음
“VO → Entity 리팩토링은 실무에서 거의 안 한다” - 처음부터 확장 가능성 고려
도메인 분리 기준 (Aggregate)
분리 판단 기준: “독립적으로 존재 가능한가?”
Aggregate란?
- 트랜잭션 일관성을 보장하는 객체 묶음
- 하나의 루트 엔티티(Root Entity)를 통해서만 외부 접근
- 함께 변경되고, 함께 저장되는 단위
같은 애그리게이트
- 생명주기가 완전히 종속된 관계
- 루트 엔티티 없이는 의미 없음
- 트랜잭션 경계를 함께 함
- 예: 주문-주문아이템, 장바구니-장바구니아이템
별도 애그리게이트
- 독립적인 생명주기
- 서로 다른 트랜잭션으로 관리
- 각자의 루트 엔티티 보유
- 예: 사용자-포인트, 상품-주문
핵심: 절대적인 기준은 없다
- Address 예시:
- 일반 서비스: Address를 VO로 사용 (단순 데이터)
- 우체국 서비스: Address를 Entity로 관리 (주소 추적/변경 이력 필요)
- 비즈니스 요구사항에 따라 같은 개념도 다르게 설계
2. API 설계 패턴
주문-결제 API 설계 시 선택지
핵심: 정답은 없다. 요구사항에 따라 선택하고, 근거를 설명할 수 있어야 한다.
설계 선택지
| 선택지 | 구조 | 장점 | 단점 |
|---|---|---|---|
| 1. API 통합 | POST /orders (주문+결제 한 번에) | - 구현 단순 - 클라이언트 호출 1번 | - 긴 트랜잭션 - Lock 과다 - 결제 실패 시 전체 롤백 |
| 2. 트랜잭션 분리 | POST /orders (내부에서 주문/결제 트랜잭션 분리) | - API 1개 유지 - 트랜잭션 경계 제어 | - 내부 복잡도 증가 - 부분 실패 처리 복잡 |
| 3. API 분리 | POST /orders POST /orders/{id}/payment | - 명확한 책임 분리 - 재시도 용이 - 고객 경험 개선 | - 클라이언트 복잡도 증가 - 상태 관리 필요 |
선택 기준 예시
케이스 1: 간단한 서비스 (MVP)
- 선택: API 통합
- 이유: 구현 속도 우선, 트래픽 적음, 복잡도 최소화
케이스 2: 결제 실패 빈번
- 선택: API 분리
- 이유:
- 결제 실패 시 주문까지 롤백? - 고객이 다른 결제수단 선택 불가
- 주문 유지 - 재시도 가능
- 고객 경험 개선
설계 시 질문할 것
- 결제 실패 시 주문은 어떻게 되어야 하는가?
- 고객이 다른 결제수단을 시도할 수 있어야 하는가?
- 트랜잭션 길이가 시스템 성능에 영향을 주는가?
- 클라이언트 복잡도 증가를 감수할 수 있는가?
좋아요 API 멱등성 설계
멱등성에 대한 오해와 이해
초기 의문
- 첫 요청: 201 Created
- 재요청: 200 OK (또는 409 Conflict)
- HTTP 상태 코드가 다른데 멱등한가?
학습 후 이해
- 멱등성의 정의: “몇 번을 요청해도 결과(리소스 상태)가 동일”
- HTTP 상태 코드가 달라도 됨
- 중요한 건: 서버의 최종 상태가 동일한가
예시
1
2
3
4
1번 좋아요 → product_like 생성 (201)
2번 좋아요 → product_like 그대로 유지 (200/409)
3번 좋아요 → product_like 그대로 유지 (200/409)
→ 결과: 좋아요 1개 (멱등함)
멱등성 구현 방법 선택지
| 방법 | 구현 | 장점 | 단점 |
|---|---|---|---|
| 1. DB 제약조건 | UNIQUE(product_id, user_id) | - DB 레벨 보장 - 구현 단순 | - 예외 처리 필요 - DB 부하 |
| 2. 애플리케이션 체크 | SELECT → 존재 확인 → INSERT | - 세밀한 제어 - 응답 커스터마이징 | - Race Condition 가능 - 코드 복잡도 증가 |
| 3. 락 방식 | SELECT FOR UPDATE → INSERT | - Race Condition 방지 - DB 제약 없이도 가능 | - 성능 오버헤드 - 데드락 가능성 - 트랜잭션 길이 증가 |
| 4. 혼합 방식 | 락 or 체크 + UNIQUE 제약 | - 이중 안전장치 - 명확한 응답 | - 복잡도 최대 |
구현 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
// 방법 1: DB 제약조건 (예외 처리)
@Table(uniqueConstraints = @UniqueConstraint(columnNames = {"product_id", "user_id"}))
class ProductLike {
// Duplicate 시도 시 예외 발생 → 409 Conflict 반환
}
// 방법 2: 애플리케이션 체크
@PostMapping("/products/{id}/likes")
public ResponseEntity<Void> likeProduct(@PathVariable Long id, @UserId String userId) {
ProductLike like = productLikeRepository.findByProductIdAndUserId(id, userId);
if (like != null) {
return ResponseEntity.ok().build(); // 200 OK (멱등성 보장)
}
productLikeRepository.save(new ProductLike(id, userId));
return ResponseEntity.status(HttpStatus.CREATED).build(); // 201 Created
}
// 방법 3: 락 방식 (Pessimistic Lock)
@Transactional
@PostMapping("/products/{id}/likes")
public ResponseEntity<Void> likeProduct(@PathVariable Long id, @UserId String userId) {
// SELECT FOR UPDATE로 Row Lock 획득
Product product = productRepository.findByIdWithLock(id);
ProductLike like = productLikeRepository.findByProductIdAndUserId(id, userId);
if (like != null) {
return ResponseEntity.ok().build();
}
productLikeRepository.save(new ProductLike(id, userId));
return ResponseEntity.status(HttpStatus.CREATED).build();
}
Race Condition 고려사항
문제 상황
- 동시에 두 요청이 “좋아요 없음” 확인 → 둘 다 INSERT 시도
- 결과: 중복 생성 가능
대응 방향
- DB 제약조건: DB 레벨에서 중복 차단 (두 번째 INSERT 실패)
- 락 사용: 동시 접근 제어 (먼저 온 요청 처리 완료까지 대기)
- 혼합: 락으로 대부분 방지 + DB 제약으로 최종 안전장치
선택 기준
- 간단한 서비스 + 트래픽 낮음: 애플리케이션 체크 (명확한 응답)
- 대규모 트래픽 + 단순 구조: DB 제약조건 (구현 단순, DB 레벨 보장)
- 트랜잭션 제어 필요: 락 방식 (세밀한 제어, 데드락 주의)
- 엔터프라이즈: 혼합 방식 (안정성 최우선)
확장성 고려사항: 규모에 따른 읽기/쓰기 트레이드오프
핵심: 읽기가 훨씬 빈번한 상황에서 쓰기 비용을 높여 읽기 비용을 낮춤
요구사항 가정
- 사용자: 1만 명
- 상품당 좋아요: 1만 개
- 목록 페이지에서 각 상품의 좋아요 수 표시 필요
문제 상황
- 매번
COUNT(*)쿼리 실행 → 읽기 부하 급증 - 목록 10개 → 10번의 집계 쿼리
- 페이지 로딩마다 반복
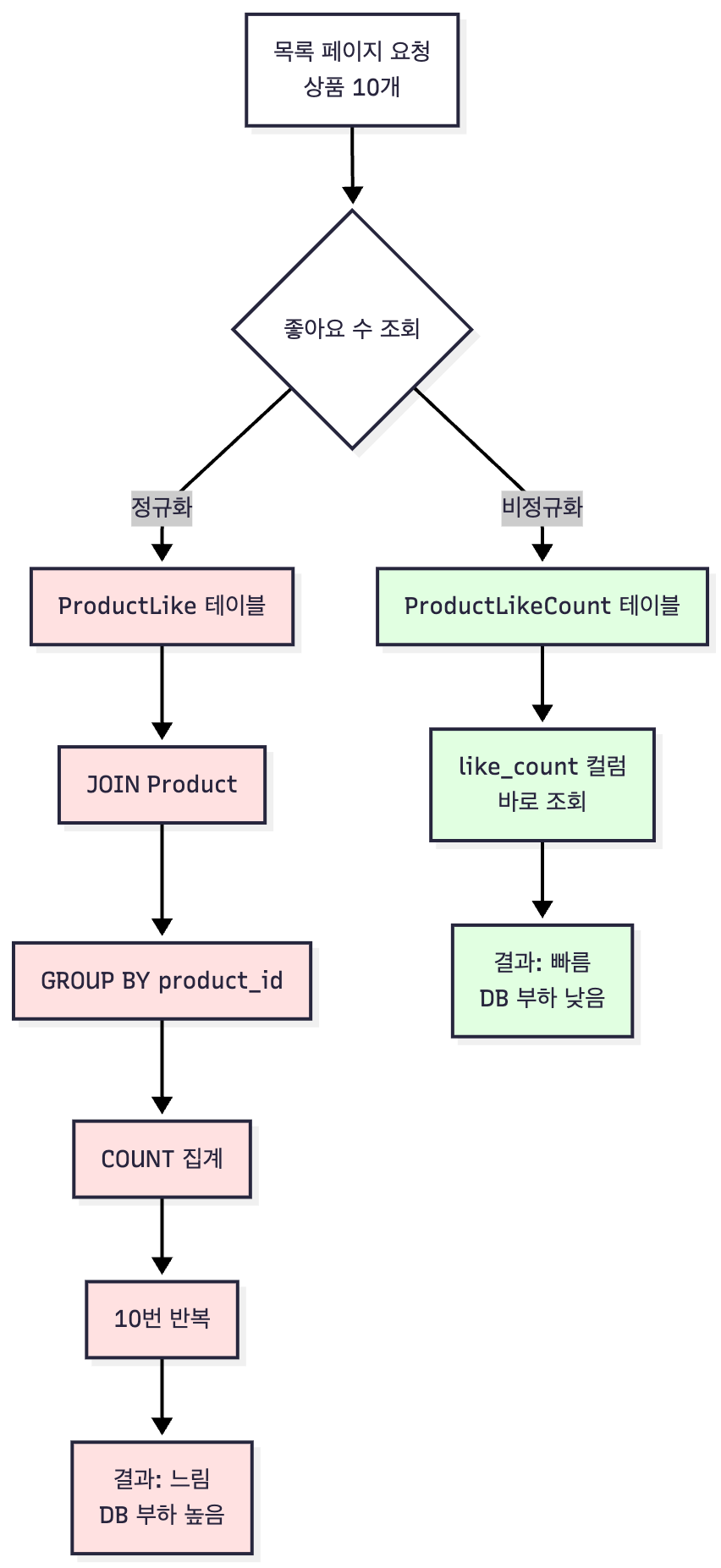
해결: 비정규화 (좋아요 수 별도 저장)
| 항목 | ProductLike 테이블 (정규화) | ProductLikeCount 테이블 (비정규화) |
|---|---|---|
| 용도 | 좋아요 생성/삭제 (쓰기) | 좋아요 수 조회 (읽기) |
| 데이터 | product_id, user_id | product_id, like_count |
| 쓰기 비용 | 낮음 (INSERT/DELETE만) | 높음 (UPDATE 추가) |
| 읽기 비용 | 높음 (매번 COUNT) | 낮음 (단순 SELECT) |
트레이드오프
- 장점: 읽기 성능 대폭 개선 (집계 → 조회)
- 단점: 쓰기 복잡도 증가 (좋아요 토글 시 count도 업데이트)
3. 설계 문서화 전략
핵심 인사이트: 문서는 독자를 위한 것
모든 문서화의 목표는 읽는 사람이 쉽게 이해할 수 있도록 작성하는 것:
- 미래의 나, 팀원, 새로운 개발자가 컨텍스트를 빠르게 파악할 수 있어야 함
- 복잡도를 관리하고, 의사결정 배경을 명확히 기록
- 친절한 문서는 유지보수 비용을 대폭 줄임
시퀀스 다이어그램 작성 원칙
독자 중심 복잡도 관리
- 50+ 라인: 과도함 → 읽는 사람 부담 증가
- 성공/실패 케이스 분리: 한 다이어그램에 모든 분기 넣지 말 것
- 핵심 + 상세 분리: 핵심 플로우만 보여주고 상세 플로우는 별첨
표현해야 할 것
- 데이터 변환 과정 (DTO 레이어별 변화)
- 트랜잭션 경계 (어디서 시작/종료되는지)
- 비동기 처리 구간 (응답 타이밍 이해를 위해)
피해야 할 것
- 추상화 레벨 혼재 (하이레벨 개념 + 메서드 호출 세부사항)
- 과도한 상세화 (모든 메서드 호출까지 표현)
- 읽기 어려운 복잡한 분기
실무 ERD 컨벤션
명명 규칙과 표준 컬럼
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
-- 독자가 이해하기 쉬운 컨벤션
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
ref_user_id BIGINT NOT NULL, -- 참조임을 명시 (ref_)
created_at TIMESTAMP NOT NULL,
updated_at TIMESTAMP NOT NULL,
deleted_at TIMESTAMP NULL -- Soft Delete용
);
-- 의도가 불명확한 컨벤션
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT, -- 참조인지 자체 필드인지 애매
deleted_yn CHAR(1) -- 삭제 시점 추적 불가
);
컨벤션 배경
- ref_ 접두사: 외래키 참조임을 명확히 표현 (읽는 사람이 관계 즉시 파악)
- deleted_at (not deleted_yn):
- 삭제 시점 추적 가능 → 복구 시 유용
- 언제 삭제되었는지 추적 가능 (감사 로그)
- created_at / updated_at: 모든 테이블 필수 (데이터 변화 추적)
실무에서 자주 쓰는 패턴
- 상태 관리:
status(VARCHAR) 또는state(ENUM) - 버전 관리:
version(BIGINT) - Optimistic Lock - 감사 필드:
created_by,updated_by- 누가 변경했는지
ADR (Architecture Decision Records)
ADR이 필요한 이유
- “왜 그 시점에 그런 결정을 했는지” 기록 → 컨텍스트 손실 방지
- 트레이드오프 명시 → 미래 유지보수자가 함부로 바꾸지 않도록
- 의사결정 과정 공유 → 팀 학습 자료
ADR 권장 템플릿 (경량 문서 방식)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
# ADR-001: OrderItem을 Entity로 설계
**상태**: 승인 | 작성일: 2024-11-09
## 배경
- 문제: OrderItem을 VO로 설계할지 Entity로 설계할지 결정 필요
- 제약: 부분 반품, 개별 배송 상태 추적 가능성 고려
- 고려 요소: 향후 확장 가능성 vs 초기 복잡도
## 결정
OrderItem을 Value Object가 아닌 **Entity로 설계**
## 근거
**대안 비교**:
| 옵션 | 장점 | 단점 |
|------|------|------|
| VO | - 구현 단순<br/>- 성능 우수 | - 확장 제약<br/>- 상태 관리 불가 |
| Entity | - 확장 가능<br/>- 개별 상태 관리 | - 초기 복잡도 증가 |
**Entity 선택 이유**:
1. 부분 반품 요구사항 예상 (개별 OrderItem 추적 필요)
2. 개별 배송 상태 추적 필요 (배송 중, 배송 완료 등)
3. VO → Entity 리팩토링은 실무에서 거의 불가능 (DB 마이그레이션 비용 高)
## 결과/영향
**장점**:
- 향후 확장 요구사항 대응 용이
- 개별 OrderItem 상태 관리 가능
**단점**:
- 초기 설계 복잡도 증가
- 약간의 성능 오버헤드
**리스크**: 없음 (충분히 검증된 패턴)
**후속 작업**: OrderItem 관련 Repository, Service 레이어 구현
## 관련
- 이슈: #123 (부분 반품 기능 검토)
- 참조: DDD Aggregate 설계 패턴 문서
실무 팁
- 중요한 아키텍처 결정만 ADR로 작성 (사소한 결정은 제외)
- 트레이드오프를 명확히 기록 (왜 A를 선택하고 B를 버렸는지)
- 컨텍스트 변경 시 ADR 업데이트 (결정 무효화 시 명시)
4. 실무 마인드셋
점진적 설계 철학
핵심: 과도한 설계보다 실용적 접근
피해야 할 것
- 처음부터 완벽한 설계 추구 → 실행 지연
- 불필요한 추상화 계층 미리 만들기
지향할 것
- 동작하는 코드를 먼저 만들고 점진적 개선
- 필요할 때 리팩토링
활용할 수 있는 방법들
- POC (Proof of Concept): 간단한 구현으로 도메인 모델 검증 후 정식 설계
- 반복적 리팩토링: 동작 확인 → 개선 → 재검증
- 점진적 추상화: 패턴이 보일 때 추상화 (미리 예측하지 말고)
비기능 요구사항 고려 시점
핵심: DB 종류에 따라 비기능 요구사항 구현 방식이 달라진다
기본적으로 깔고 가야 할 것
동시성 (Concurrency)
- 왜 기본인가: 웹 애플리케이션은 기본적으로 멀티 스레드 환경
- Race Condition은 DB 종류와 무관하게 발생 가능
- 애플리케이션 레벨에서도 제어 가능 (Lock, 동기화 등)
멱등성 (Idempotency)
- 왜 기본인가: 네트워크 불안정성은 항상 존재
- 클라이언트 재시도, 타임아웃 등은 일상적 시나리오
- 결제/주문 같은 중요 API는 멱등성 없으면 치명적
상황에 따라 결정
일관성 (Consistency) - (DB 의존성 높음)
- 문제: 초기에 “강한 일관성” 요구사항 넣으면 DB 선택 제약
- RDBMS: 강한 일관성 쉬움 (ACID 트랜잭션)
- NoSQL: 최종 일관성 기본 (강한 일관성 어려움)
- 결정 시점: DB 선택 후 or 데이터 특성 파악 후
- 예: 조회수는 최종 일관성 OK, 결제는 강한 일관성 필수
가용성 (Availability)
- 문제: SLA 99.9% vs 99.99%에 따라 인프라 복잡도 급증
- DB 다중화, 장애 복구 전략이 DB 종류에 따라 천차만별
- RDBMS Replication vs NoSQL Sharding
- 결정 시점: 실제 트래픽 규모 파악 후
실무 팁
- 동시성/멱등성은 설계 초기부터 고려 (나중에 추가하기 어려움)
- 일관성/가용성은 요구사항 + DB 선택 후 구체화 (무조건 넣으면 과도한 제약)
문서화 원칙
핵심: 관리 포인트를 최소화하라
문서화의 본질
- 화이트보드 토론도 문서화: 그리고 지우고 다음날 대화하는 것도 커뮤니케이션 기록
- 실제 문서 파일은 최소화: 파일로 남기는 순간 유지보수 대상이 됨
- 너무 많은 문서는 부채: 업데이트 안 되면 오히려 혼란 야기
오래 살아남는 문서의 특징
- 변경 빈도가 낮음: ADR (아키텍처 결정), 핵심 설계 원칙
- 본질적 가치: 시스템의 “왜”를 설명 (구현 세부사항이 아닌)
- 독립적: 코드 변경에 영향받지 않는 내용
실무 기준
문서화할 것
- ADR (중요한 의사결정과 트레이드오프)
- 전체 시스템 아키텍처 (큰 그림)
- 신규 팀원 온보딩 가이드
문서화 안 할 것
- 코드 읽으면 알 수 있는 것
- 자주 변경되는 세부 구현
- 자명한 로직 설명
핵심: 문서는 적을수록 좋다. 필요한 것만 남기고 관리 부담을 줄여라.
커리어 & 성장 전략
5. 3~5년차 개발자 역량
핵심 인사이트: “일머리”가 중요하다는 걸 알았다
일머리란?
- 유연성: 고집 부릴 때 vs 내려놓을 때 구분
- 팀워크: 팀 미션을 위해 자신을 내려놓고 부스팅
- 효율성: 두 번 말하지 않게 만드는 커뮤니케이션
- 태도: 일을 재밌게 만드는 능력
더 알고 싶은 것
- 그럼 일머리는 구체적으로 뭐지?
- 어떻게 기를 수 있지?
- 실무에서 어떻게 발휘하지?
6. 면접 준비 전략
핵심: 알려주는 경험을 많이 해야한다.
왜 중요한가
- 내가 아는 걸 타인에게 이해시키는 능력 = 면접의 본질
- 비유법 활용 = 깊은 이해의 증거
- 연습 없이 면접관을 이해시키려는 건 치사함
실천 방법
- 루퍼스, 동료들과 설명 연습을 많이 하기
- 복잡한 개념을 쉽게 설명하는 연습
7. 이력서 작성 전략
핵심: 수치화보다 비즈니스 임팩트
단순 수치의 함정
| 사례 | 수치 | 비즈니스 임팩트 |
|---|---|---|
| A | 1시간 → 1분 (59분 단축) | 원래 1시간마다 돌던 배치 → 사실 문제 없었음 |
| B | 10분 → 9분 (1분 단축) | 10분마다 돌아야 하는데 간당간당 → 안정성 확보 |
핵심: B가 비즈니스 임팩트가 더 크다!
돋보이는 이력서 작성법
| 평범한 이력서 | 돋보이는 이력서 |
|---|---|
| 숫자만 나열 (응답 시간 50% 개선) | “그래서 뭐가 달라졌는데?” (불안정한 서비스 → 안정화) |
| 기술 스택 나열 (Spring, Redis 사용) | “그래서 뭐를 얻었는데?” (트래픽 10배 증가 대응 가능) |
| 텍스트만 나열 | 시각적 요소 활용 (다이어그램, 흐름도 등) |
이력서 차별화 포인트
- 아키텍처 고민 과정의 시각화 추가
- 읽는 사람이 쉽게 이해할 수 있는 구조
현실 체크
- 이력서가 아무리 좋아도 면접에서 떨어질 수 있다
- 포트폴리오를 멋지게 만들어도 설명 못 하면 의미 없다
=> 핵심: 이력서 + 면접 + 기술력 다 잘해야 한다
더 알아보면 좋을 것들
이번 주 학습을 통해 발견한 역량 확장 영역
표준화된 개발 문서 포맷
- SRS (Software Requirements Specification): 소프트웨어 요구사항 명세서
- ADR (Architecture Decision Records): 아키텍처 의사결정 기록
- API 명세서: OpenAPI/Swagger 표준
- 시스템 설계 문서: 아키텍처 다이어그램, 플로우차트, ERD, 시퀀스 다이어그램, 유즈케이스
역량 확장 포인트: 팀 간 커뮤니케이션 능력, 문서화 표준 이해
도메인 주도 설계 (DDD)
큰 그림 설계 (어떻게 나눌까)
- Bounded Context: 시스템을 의미 있는 경계로 나누기 (주문 시스템 vs 결제 시스템)
- Ubiquitous Language: 개발자와 비즈니스 팀이 같은 용어 쓰기
세부 구현 설계 (어떻게 만들까)
- Entity: 식별자가 있는 객체 (Order, User)
- Value Object: 값으로만 구분되는 객체 (Address, Money)
- Aggregate: 함께 변경되는 객체 묶음
역량 확장 포인트: 복잡한 비즈니스 로직을 체계적으로 설계하는 능력
대용량 트래픽 처리
- 캐싱 전략: Redis 활용 (Look-Aside, Write-Through, Write-Behind)
- 부하 분산: 로드 밸런싱, 샤딩, 레플리케이션
- 성능 최적화: 인덱싱, 쿼리 최적화, 비동기 처리
- 모니터링: APM, 로그 분석, 장애 대응
역량 확장 포인트: 실무 규모의 시스템 설계 및 운영 경험