비관적 락 vs 낙관적 락: 이름부터 알아보며 상황에 맞게 선택하기

TL;DR
- 낙관적/비관적이라는 이름은 충돌에 대한 태도에서 유래했다.
- 낙관적 락: 충돌이 드물다고 가정하고, 검증 + 롤백 비용을 감수하는 방식.
- 비관적 락: 충돌이 잦을 것이라 가정하고, 미리 잠그고 줄 세우는 방식.
- 락 선택 시 충돌 빈도 외에 실패 허용 여부, 트랜잭션 길이, 재시도 비용도 고려해야 한다.
들어가면서
이커머스 시스템은 재고, 포인트, 좋아요 같은 수 많은 도메인에서 동시성 문제가 자주 발생한다.
최근 ‘주문’과 ‘좋아요’ 기능을 구현하면서 “동시에 100개 요청이 들어오면 어떻게 동시성을 제어할까?”라는 고민이 생겼다. 비관적 락, 낙관적 락이라는 해결책은 대략 알고 있었지만, 어떤 상황에서 어떤 락을 선택해야 할지 기준이 명확하지 않았다. 게다가 ‘비관적’, ‘낙관적’이라는 이름도 직관적이지 않았다. “낙관적인데 왜 락이지?”
이런 궁금증에서 시작해서, 이번 글에서는
- 왜 ‘비관적/낙관적’이라는 이름이 붙었는지
- 비관적 락과 낙관적 락이 각각 어떻게 동작하는지
- 어떤 기준으로 락을 선택하면 좋을지
를 정리해 보았다.
낙관적 락과 비관적 락 이름의 유래
‘낙관적 락’, ‘비관적 락’… 이름부터 어렵게 느껴진다. 그래서 누가, 언제, 왜 이런 이름을 붙였는지부터 찾아봤다.
1. 낙관적 락(Optimistic Lock)
“낙관적 동시성 제어(Optimistic Concurrency Control)”라는 용어는 1979년 H. T. Kung과 John T. Robinson이 VLDB 학회에서 발표한 논문 「On Optimistic Methods for Concurrency Control」에서 처음 등장했다.
이 논문의 핵심 아이디어는 기존 락 기반 방식과 달리:
“충돌이 자주 일어나지 않을 거라고 믿고, 일단 실행한 뒤, 마지막에 검증해서 문제가 있으면 되돌리자”
라는 접근이다. 논문에서는 이 방식을 왜 “optimistic”이라고 부르는지 직접 설명한다.
“These methods are ‘optimistic’ in the sense that they rely for efficiency on the hope that conflicts between transactions will not occur.” — 트랜잭션 간 충돌이 일어나지 않을 것이라는 ‘희망(hope)’에 효율성을 의존한다는 점에서 “낙관적”이다.
즉, “낙관적”이라는 이름은 “충돌은 드물 거라고 믿고, 락 대신 검증 + 롤백에 베팅하는 방식”이라는 철학을 담고 있다.
이 개념은 이후 Optimistic Concurrency Control(OCC)로 정리되었고, 애플리케이션 레벨에서는 버전 필드를 활용한 “낙관적 락” 패턴으로 이어졌다.
2. 비관적 락(Pessimistic Lock)
반대로 비관적 락은 명확한 출처를 찾기 어렵다.
1970년대부터 데이터베이스 세계에서는 이미 락 기반 동시성 제어가 표준처럼 쓰이고 있었지만, 당시에는 그냥 “락킹(locking)”이나 “2PL(Two-Phase Locking)”로만 불렀다.
그러다 1979년 Kung & Robinson이 ‘optimistic’이라는 용어를 도입하면서, 기존 락 기반 방식은 자연스럽게 pessimistic concurrency control, pessimistic locking이라 불리게 되었다.
즉, 새로 등장한 “낙관적” 방법과 대비되는 개념으로서 기존 락 방식에 “비관적”이라는 이름이 붙은 셈이다.
3. 이름에서 보이는 동작의 차이
이제 두 락의 차이를 정리해보자.
| 구분 | 비관적 락 (Pessimistic Lock) | 낙관적 락 (Optimistic Lock) |
|---|---|---|
| 동시성에 대한 가정 | 어차피 충돌 날 거라고 비관함 | 충돌은 드물 거라고 낙관함 |
| 기본 전략 | 먼저 잠그고 나만 쓰겠다 | 일단 실행하고, 나중에 검증 |
| 제어 방식 | 락을 잡고 다른 트랜잭션은 대기 | 버전 비교로 충돌 감지, 충돌 시 재시도 |
| 비용 | 대기 시간 감수 | 재시도 비용 감수 |
결국 두 락의 이름은 “충돌에 대한 태도”를 담고 있고, 이 태도가 “대기 vs 재시도”라는 비용 선택으로 이어진다.
낙관적 락
1. 개념
낙관적 락의 핵심은 “일단 진행하고, 커밋 직전에 검증한다”는 것이다. 먼저 잠그고 대기하는 게 아니라, 충돌이 없을 거라 가정하고 작업을 수행한 뒤, 마지막 순간에 “내가 작업하는 동안 데이터가 바뀌었는가?”를 확인한다. 바뀌었다면 롤백하고 재시도한다.
2. 동작 방식
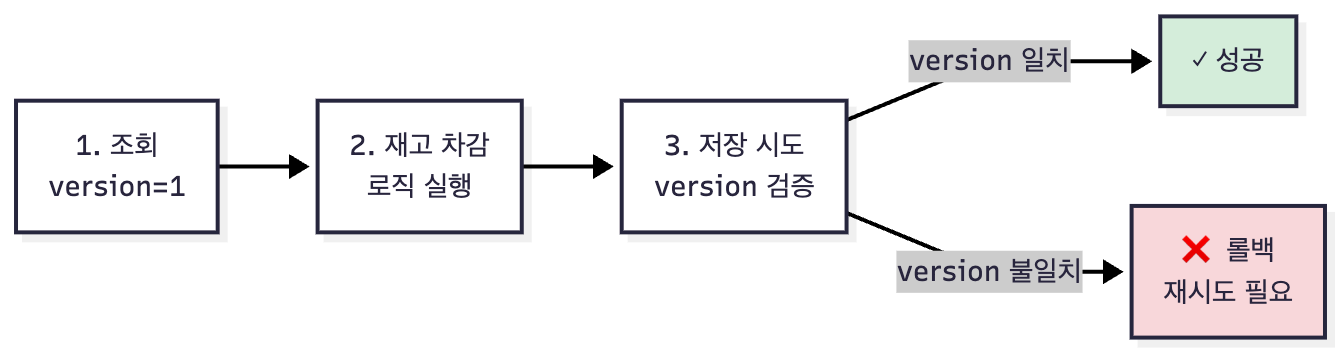 조회 → 작업 수행 → 커밋 직전 검증 → 충돌 시 롤백/재시도
조회 → 작업 수행 → 커밋 직전 검증 → 충돌 시 롤백/재시도
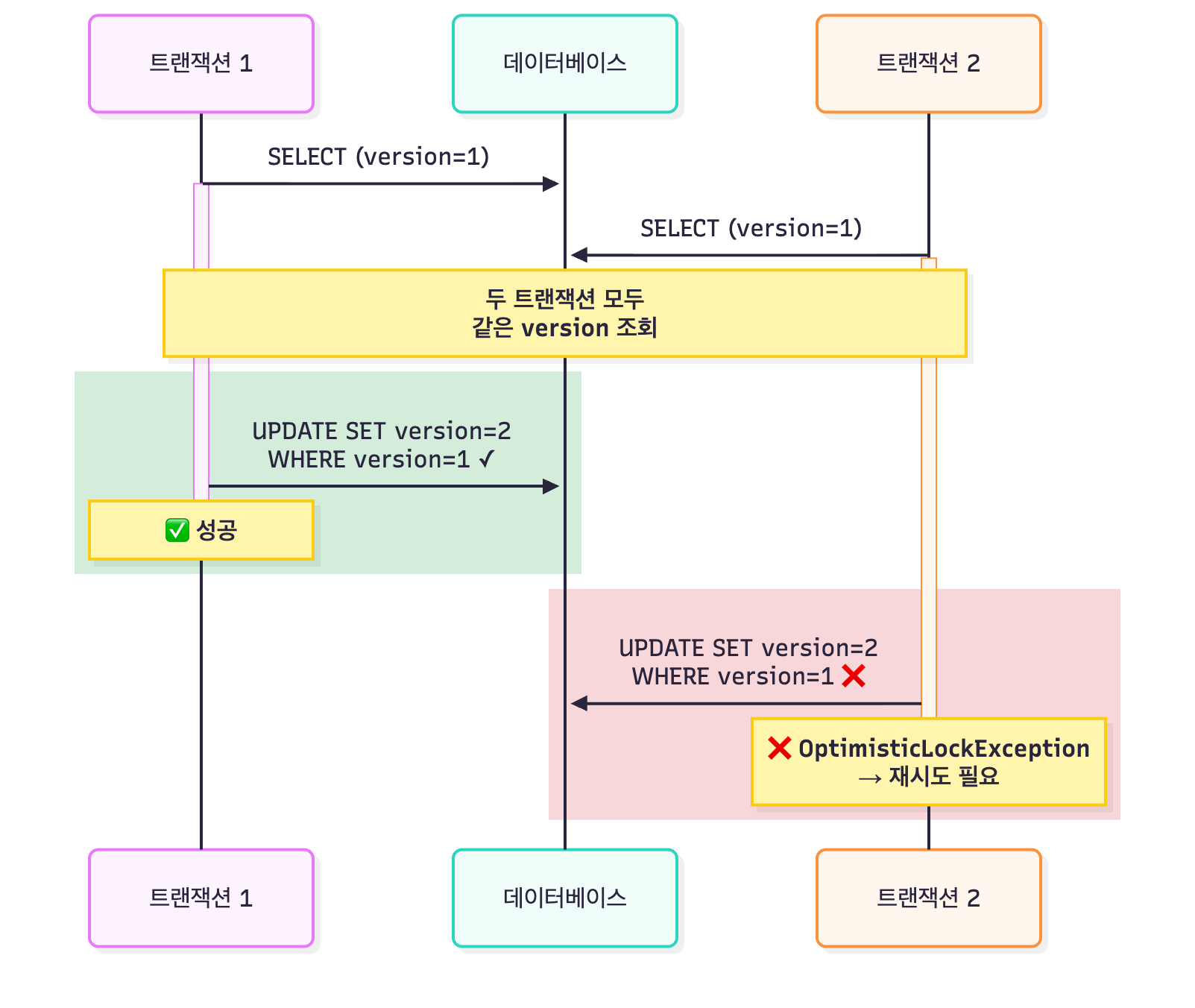 두 트랜잭션이 동시에 같은 데이터를 수정할 때, 먼저 커밋한 쪽이 성공하고 나중 쪽은 충돌로 실패한다.
두 트랜잭션이 동시에 같은 데이터를 수정할 때, 먼저 커밋한 쪽이 성공하고 나중 쪽은 충돌로 실패한다.
UPDATE의 경우
- 데이터를 읽을 때 현재 상태를 기억해둔다.
- 비즈니스 로직을 수행한다. (중간에 다른 트랜잭션과 부딪혀도 신경 안 씀)
- 커밋 직전에 “내가 읽은 이후로 누가 바꿨는가?”를 확인한다.
- 안 바뀌었으면 → 업데이트 성공
- 바뀌었으면 → 충돌로 판단, 롤백
INSERT의 경우
- 비교할 기존 값이 없으므로 위 방식으로는 충돌을 감지할 수 없다.
- 대신 DB 제약조건(UNIQUE 등)으로 중복을 감지한다.
충돌 감지 시
충돌이 감지되면 예외를 던지고, 애플리케이션이 재시도 / 포기 / 사용자 안내를 결정한다.
JPA에서 낙관적 락 구현하기
가장 일반적인 방법은 버전 필드(@Version)를 사용하는 것이다.
기술 스택: 이 글에서는 JPA와 Spring을 기반으로 설명한다.
1) Entity에 버전 필드 추가
1
2
3
4
5
6
7
8
9
10
@Entity
public class ProductLike {
@Id @GeneratedValue
private Long id;
@Version
private Long version;
// ...
}
JPA는 UPDATE 시 자동으로 다음 SQL을 생성한다:
1
2
3
UPDATE product_like
SET ..., version = version + 1
WHERE id = ? AND version = ?;
version이 일치할 때만 업데이트- 다른 트랜잭션이 먼저 커밋하면 WHERE 불일치 →
OptimisticLockException
2) 재시도 전략
충돌 시 예외가 발생하므로, 재시도 로직을 설계해야 한다.
1
2
3
4
5
6
7
8
9
@Retryable(
retryFor = OptimisticLockException.class,
maxAttempts = 3,
backoff = @Backoff(delay = 100)
)
@Transactional
public void updateProduct(...) {
// 조회 → 수정 → 저장
}
정리
@Version하나로 적용 가능- JPA가 버전 검증 SQL 자동 생성
- 충돌 시 예외 → 재시도로 처리
3. 주의할 점
낙관적 락은 “충돌은 드물 것”이라는 가정 위에서 성립한다. 재시도는 설계에 포함된 정상 흐름이지만, 같은 자원에 요청이 집중되면 문제가 된다.
충돌 → 재시도 → 또 충돌… 루프에 빠지면서, 재시도 자체가 부하가 되어 상황을 악화시킬 수 있다.
이런 구간에서는 비관적 락이나 다른 동시성 제어 방식을 고려해야 한다.
비관적 락
1. 개념
비관적 락의 핵심은 “먼저 잠그고, 나만 쓴다”는 것이다. 충돌이 날 거라고 가정하고, 자원을 먼저 선점해서 다른 트랜잭션이 접근하지 못하게 막는다. 작업이 끝나면 락을 해제한다.
2. 동작 방식
 락 획득 → 작업 수행 → 커밋/롤백 → 락 해제
락 획득 → 작업 수행 → 커밋/롤백 → 락 해제
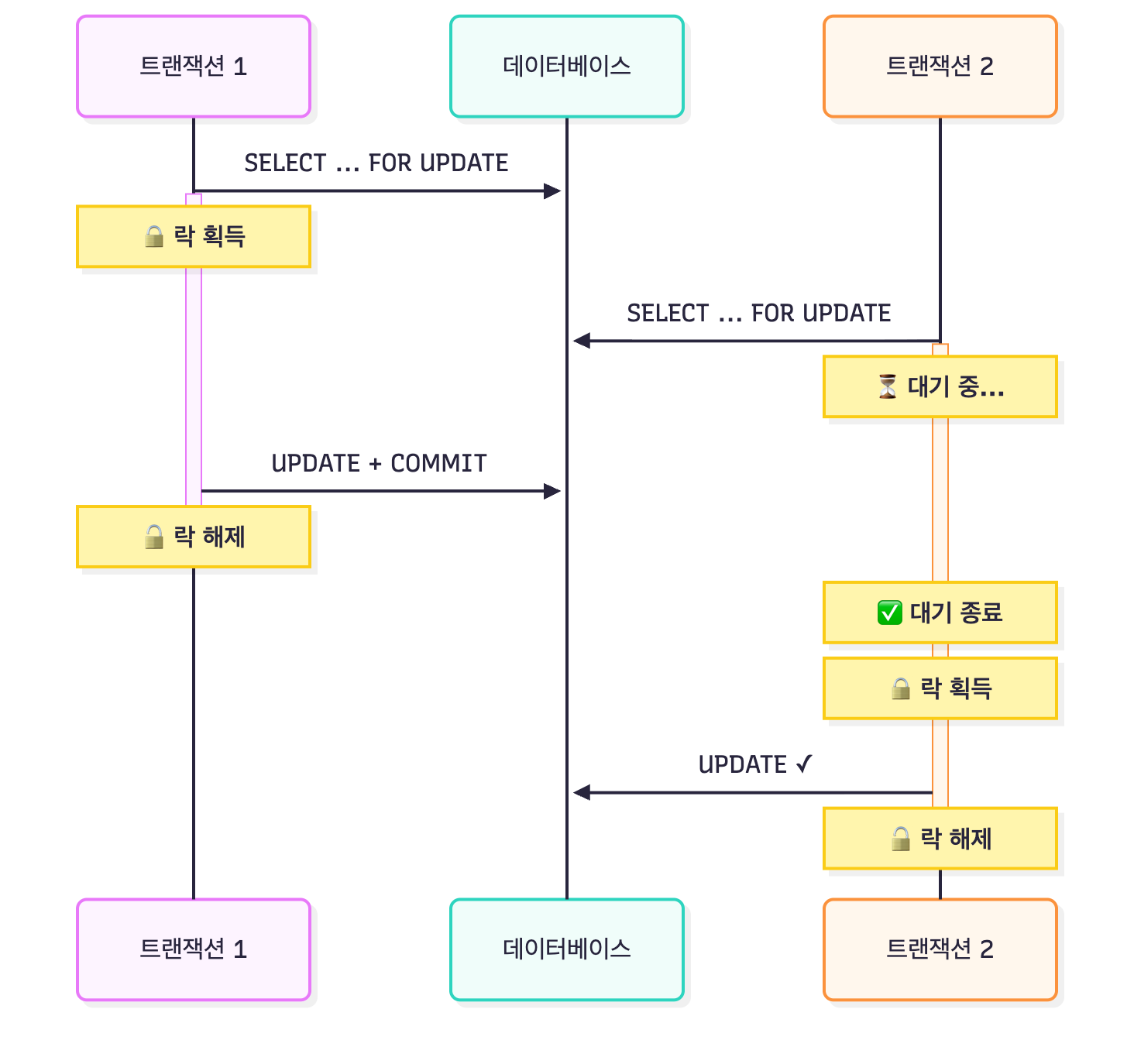 두 트랜잭션이 동시에 같은 데이터를 요청할 때, 먼저 락을 잡은 쪽이 작업하고 나머지는 대기한다.
두 트랜잭션이 동시에 같은 데이터를 요청할 때, 먼저 락을 잡은 쪽이 작업하고 나머지는 대기한다.
JPA에서 비관적 락 구현하기
기술 스택: 이 글에서는 JPA와 Spring을 기반으로 설명한다.
1) FOR UPDATE로 락 획득
1
SELECT * FROM product WHERE id = 1 FOR UPDATE;
id = 1레코드에 배타 락(Exclusive Lock)을 건다- 다른 트랜잭션은 락이 풀릴 때까지 대기
- COMMIT 또는 ROLLBACK 시 락 해제
2) Repository와 Service 구현
1
2
3
4
5
6
7
8
9
10
11
12
// Repository
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("SELECT p FROM Product p WHERE p.id = :id")
Optional<Product> findByIdForUpdate(@Param("id") Long id);
// Service
@Transactional // 필수! 트랜잭션 없으면 락이 즉시 해제됨
public void decreaseStock(Long productId, int quantity) {
Product product = productRepository.findByIdForUpdate(productId)
.orElseThrow(...);
product.decreaseStock(quantity);
}
정리
@Lock(PESSIMISTIC_WRITE)+@Transactional로 적용- 트랜잭션 범위 = 락 유지 시간
- 다른 트랜잭션은 락이 풀릴 때까지 대기
락의 범위
비관적 락은 “락이 어느 범위까지 걸리는지” 이해하는 것이 중요하다. 핵심은 “락은 인덱스 기준으로 범위가 정해진다”는 점이다.
더 알아보기: InnoDB는 Row Lock, Gap Lock, Next-Key Lock을 인덱스 단위로 사용합니다. 자세한 내용은 부록의 “InnoDB 락 메커니즘 이해하기”를 참고하세요.
3. 주의할 점
비관적 락은 트랜잭션 범위 = 락 유지 시간이다. 트랜잭션이 길어지면 뒤따르는 요청들이 줄줄이 대기하고, 데드락 위험도 증가한다.
따라서 트랜잭션은 최대한 짧게 유지해야 한다:
- 조회 + 필수 UPDATE만 포함
- 외부 API, 알림 등은 트랜잭션 밖으로 (도메인 이벤트, Outbox 패턴)
락 선택 기준
처음에는 “충돌이 많으면 비관적, 적으면 낙관적”이라고 단순하게 생각했다. 하지만 실제로는 충돌 빈도 외에도 실패 허용 여부, 트랜잭션 길이, 재시도/대기 비용을 함께 고려해야 한다.
최근 커머스 과제에서 포인트 차감과 좋아요를 구현하면서 이 기준들을 적용해봤다.
포인트 차감 → 비관적 락
- 실패 허용: 불가. 주문/결제와 엮인 중요 데이터
- 트랜잭션 길이: 짧음. 조회 + 차감만
- 비용 선택: 대기 비용 감수 → 재시도 복잡성 회피
포인트는 “일단 해보고 실패하면 다시”로 접근하기엔 리스크가 크다. 재시도 로직이 주문/결제 흐름과 맞물리면 정합성 문제가 생길 수 있어서, 락 대기 시간을 감수하고 한 번에 안전하게 처리하는 쪽을 택했다.
좋아요 → 낙관적 락
- 실패 허용: 가능. 실패해도 다시 누르면 됨
- 트랜잭션 길이: 짧음. INSERT만
- 비용 선택: 재시도 비용 감수 (발생 빈도 낮음)
같은 사용자가 동시에 같은 상품에 좋아요를 누를 확률은 거의 없다. UNIQUE 제약으로 중복을 막고, 충돌 시 예외로 처리했다. 매번 락을 잡는 비용보다, 드문 충돌을 예외로 처리하는 게 낫다고 판단했다.
결국 두 락의 차이는 “실패를 어디서 감지하고, 어떻게 다룰 것인가”에 대한 설계로 보였다. 포인트는 충돌을 비관적으로 보고 애초에 막았고, 좋아요는 일단 시도하고 드물게 실패하면 수용했다.
앞으로는 이런 개념들을 단순히 외우기보다는,
- 어떤 문제를 풀기 위해 등장했는지
- 어떤 상황에서 적절한지
- 실제 적용할 때 주의할 점은 무엇인지
를 함께 생각하면서 가져가려 한다.
부록
InnoDB 락 메커니즘 이해하기
핵심: 락은 인덱스 키를 대상으로 건다
InnoDB의 락은 “인덱스 키(또는 키 범위)” 에 걸린다. 따라서 어떤 쿼리가 어떤 인덱스를 타느냐에 따라 락의 범위가 완전히 달라진다.
InnoDB는 세 가지 방식으로 락을 건다:
1) Row Lock - 특정 키 하나만 잠금
가장 좁은 범위의 락이다. 인덱스의 특정 키 하나만 잠근다.
1
2
-- PK 인덱스: 1, 5, 10, 20, 30
SELECT * FROM product WHERE id = 10 FOR UPDATE;
- 락 대상:
id = 10키만 - 효과: 다른 트랜잭션은
id = 10키를 수정/삭제/잠금 조회할 수 없다 - 범위:
id = 5나id = 20은 자유롭게 수정 가능
2) Gap Lock - 키 사이의 빈 구간 잠금
키와 키 사이의 빈 공간(갭) 을 잠근다. 새로운 INSERT를 막기 위한 락이다.
1
2
-- 인덱스 키: 10, 20이 있을 때
-- (10, 20) 구간에 갭 락이 걸림
- 락 대상:
10과20사이의 빈 구간 - 효과:
11 ~ 19값은INSERT가 차단된다 - 목적: 범위 조회 시 “읽은 범위에 새 키가 끼어드는 것(팬텀)” 방지
- 주의: 범위를 넓게 잡으면 많은
INSERT가 막힐 수 있다
3) Next-Key Lock - 키 + 앞 구간을 함께 잠금
Row Lock과 Gap Lock을 합친 형태다. “특정 키 + 그 앞 구간” 까지 한 번에 잠근다. InnoDB의 REPEATABLE READ에서 기본 락 방식이다.
1
2
-- PK 인덱스: 5, 10, 20이 있을 때
SELECT * FROM product WHERE id = 10 FOR UPDATE;
- 락 대상:
id = 10키 +(5, 10)구간 - 효과:
id = 10수정/삭제 차단 +6 ~ 9값의INSERT도 차단 - 목적: REPEATABLE READ에서 읽기 일관성과 팬텀 방지를 동시에 달성
왜 이게 중요한가?
인덱스가 없거나 잘못된 인덱스를 타면 의도보다 훨씬 넓은 범위에 락이 걸린다.
1
2
-- status에 인덱스가 없다면?
SELECT * FROM orders WHERE status = 'PENDING' FOR UPDATE;
→ 테이블 전체에 락이 걸릴 수 있다 (풀스캔) → 모든 다른 트랜잭션의 INSERT/UPDATE가 대기하게 된다 → 비관적 락을 쓸 때는 반드시 인덱스 설계를 함께 고려해야 한다
참고
- On Optimistic Methods for Concurrency Control (H. T. Kung, J. T. Robinson, VLDB 1979) - 낙관적 동시성 제어 개념의 최초 제안
- MySQL 8.x - InnoDB Locking - Row Lock, Gap Lock, Next-Key Lock 동작 방식
- MySQL 8.x - InnoDB Index Types - 클러스터링 인덱스 구조 및 B+Tree 설명
- Wikipedia - Optimistic Concurrency Control - 낙관적 동시성 제어 개념 정리
- Wikipedia - Concurrency Control - 동시성 제어 분류 및 개념
- Mark-Kim 블로그 - MySQL InnoDB Lock - Record Lock, Gap Lock, Next-Key Lock 한글 설명