프로젝트에서 발견한 슬로우 쿼리 개선기
슬로우 쿼리 개선
사내 서비스 개선 프로젝트 후 모니터링 과정에서 쿼리 실행 시간이 1초 이상 소요되는 쿼리를 발견하였고 이를 개선해보았습니다.
첫 번째 슬로우 쿼리
개선 전 슬로우 쿼리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
SELECT c.*,
(subquery1) AS total_price,
(subquery2) AS last_payment_seq,
(subquery3) AS last_payment_state,
... //일부 생략
FROM consult c
LEFT JOIN consult_group cg on cg.seq = c.consult_group_seq
LEFT JOIN hospital_patient hp on hp.seq = c.hospital_patient_seq
LEFT JOIN tb_doctor td ON c.doctor_seq = td.seq
... //일부 생략
WHERE c.hospital_seq = #{hospitalSeq}
AND (
c.status in ('RSV-REQ', 'RSV-ACC', 'CON-REQ')
OR (
DATE_FORMAT(c.request_dtm, '%Y%m%d') = ${searchDt}
OR DATE_FORMAT(c.accept_dtm, '%Y%m%d') = ${searchDt}
OR DATE_FORMAT(c.reservation_dtm, '%Y%m%d') = ${searchDt}
OR DATE_FORMAT(c.cancel_dtm, '%Y%m%d') = ${searchDt}
OR DATE_FORMAT(c.end_dtm, '%Y%m%d') = ${searchDt}
)
)
ORDER BY seq asc;
가장 빈번하게 발생한 슬로우 쿼리는 첫 화면에서 사용되는 조회 쿼리였습니다.
조회 시 인덱스를 제대로 활용하지 못하고 있었기 때문에 옵티마이저의 예측 레코드가 rows가 5만 건이였습니다.
개선 전 쿼리 실행계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | c | null | ref | IDX_hospital_seq_type_status,IDX_status,cardList index | IDX_hospital_seq_type_status | 4 | const | 51212 | 61.15 | Using where; Using filesort |
| 1 | PRIMARY | cg | null | eq_ref | PRIMARY | PRIMARY | 4 | c.consult_group_seq | 1 | 100 | null |
| 1 | PRIMARY | hp | null | eq_ref | PRIMARY | PRIMARY | 4 | c.hospital_patient_seq | 1 | 100 | null |
| 1 | PRIMARY | td | null | eq_ref | PRIMARY | PRIMARY | 4 | c.doctor_seq | 1 | 100 | null |
| 11 | DEPENDENT SUBQUERY | consult | null | ref | FK_consult_group_TO_consult | FK_consult_group_TO_consult | 4 | cg.seq | 1 | 10 | Using where |
| 생략 |
개선 포인트
개선 포인트1
SQL에서 데이터 포맷 함수등으로 인덱스가 설정된 컬럼을 변형하였다면, 인덱스가 설정되어 있어도 옵티마이저가 인덱스를 사용하지 않을 수 있습니다.
조회 컬럼을 DATE_FORMAT 함수로 변형시키지 않고, 조건을 BETWEEN 키워드 또는 부등호로 변경하여 조회하여 인덱스 레인지 스캔 타입으로 조회 될 수 있도록 변경합니다.
Mybatis에서는 부등호를 사용하기 위해 CDATA를 사용해야하기 때문에 가독성이 안좋다고 판단하였기 때문에 BETWEEN을 선택하였습니다.
1
2
3
4
5
6
7
8
9
10
AND (
c.status in ('RSV-REQ', 'RSV-ACC', 'CON-REQ')
OR (
c.request_dtm BETWEEN '20240425' AND '20240426'
OR c.accept_dtm BETWEEN '20240425' AND '20240426'
OR c.reservation_dtm BETWEEN '20240425' AND '20240426'
OR c.cancel_dtm BETWEEN '20240425' AND '20240426'
OR c.end_dtm BETWEEN '20240425' AND '20240426'
)
)
조회 속도를 비교해보았습니다.
조회 조건에서 사용하는 모든 컬럼에 인덱스 설정하기 전이기 때문에 약간의 속도 향상만 확인할 수 있었습니다.
| 회 | dataformat(ms) | between(ms) |
|---|---|---|
| 1 | 438 | 414 |
| 2 | 372 | 436 |
| 3 | 470 | 336 |
| 4 | 449 | 440 |
| 5 | 373 | 366 |
| 평균 | 420 | 398.4 |
개선 포인트2
기존에 사용하던 복합 인덱스는 일부만 인덱스를 탔기 때문에 다른 컬럼(request_dtm, accept_dtm, reservation_dtm, cancel_dtm, end_dtm)에도 인덱스를 추가해주었습니다.
인덱스 비용을 계산해 보면 인덱스를 5개를 추가하였기 때문에 1건의 레코드가 추가 될 때 인덱스를 추가하기 전보다 대략 1.5*5 비용이 더 들게 됩니다. 하지만 가장 빈번하게 호출되는 쿼리이면서
request_dtm, reservation_dtm은 데이터 입력 시점에만 들어오고, accept_dtm, cancel_dtm,end_dtm은 단계별로 한 번씩만 업데이트 컬럼이기 때문에 변경으로 인한 인덱스 업데이트 비용이 조회가 느린 비용 보다 크지 않다고 판단하였습니다. 또한 인덱스 설정은 다른 쿼리에서도 활용이 가능하였습니다.
BETWEEN으로 변경하고 인덱스를 추가한 뒤 실행 계획을 확인한 결과
예측 레코드 건수가 51,212건에서 1,405건으로 97.26% 감소하였습니다.
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | cv2 | null | index_merge | IDX_hospital_seq_type_status,IDX_status,IDX_accept_dtm,IDX_cancel_dtm,IDX_end_dtm,IDX_request_dtm,IDX_reservation_dtm | IDX_status,IDX_request_dtm,IDX_accept_dtm,IDX_reservation_dtm,IDX_cancel_dtm,IDX_end_dtm | 28,6,6,6,6,6 | null | 1405 | 50 | Using sort_union(IDX_status,IDX_request_dtm,IDX_accept_dtm,IDX_reservation_dtm,IDX_cancel_dtm,IDX_end_dtm); Using where; Using filesort |
개선 시도1
서브 쿼리를 제거하여 실행 시간을 비교해보았습니다.
| 서브쿼리 제거 전(ms) | 서브쿼리 제거 후(ms) | |
|---|---|---|
| 1회 | 391 | 376 |
큰 성능 향상은 없었습니다.
개선 시도 2
where절에 많은 OR 조건이 조회 속도를 느리게 하는 범인이 아닐까 추측하였습니다.
OR 조건을 분리하여 조회하고 서버에서 합치는 방식으로 시도해보았습니다.
| 변경 전 | 변경 후 | |
|---|---|---|
| 1차 | 169ms | 261ms |
| 2차 | 407ms | 710ms |
이 방법은 중복된 코드가 증가하여 유지보수가 어려워졌고, SQL 호출 횟수 증가 및 서버에서 결과를 합치는 로직이 추가되어 메소드 실행 시간이 기존보다 더 증가하였습니다.
개선 결과
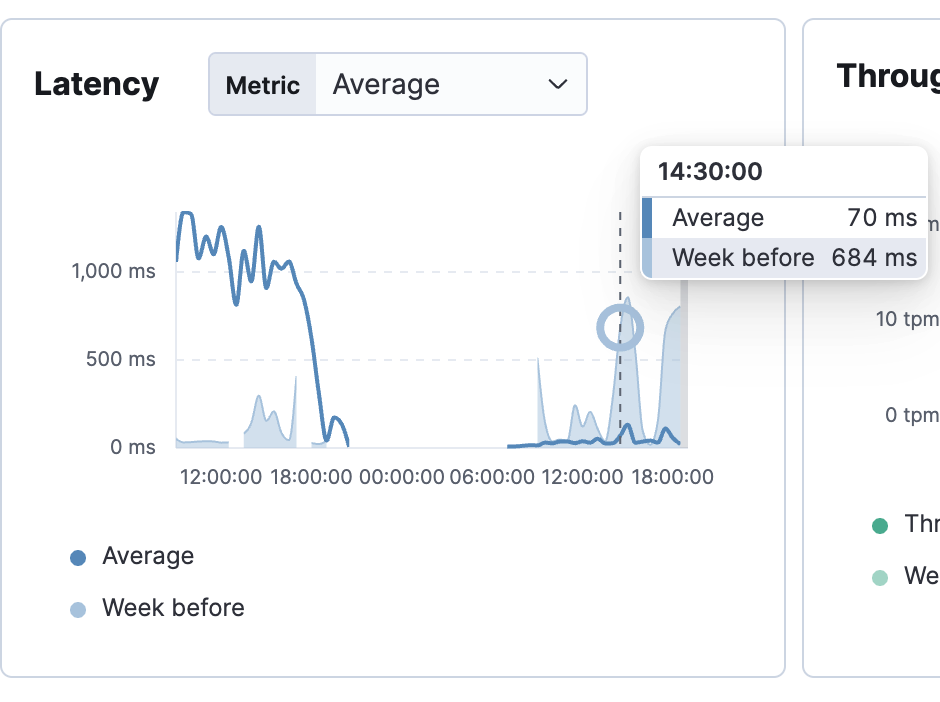
슬로우 쿼리1 개선 이후 평균 1,000ms가 넘어가는 지연시간이 100ms로 낮아졌습니다.
두 번째 슬로우 쿼리
개선 전 슬로우 쿼리
검색어를 포함하고 있는 이름, 전화번호, 생년월일을 검색하는 쿼리입니다.
1
2
3
4
5
6
7
8
9
10
SELECT DISTINCT hp.seq, hp.name, hp.hp_no, hp.patient_account_seq
FROM hospital_patient hp
WHERE hp.hospital_seq = 150
AND hp.name is not null
AND hp.hp_no is not null
AND hp.name NOT LIKE ''
AND hp.hp_no NOT LIKE ''
... 일부 생략
AND (hp.name LIKE CONCAT('%', '검색어', '%') OR hp.hp_no LIKE CONCAT('%', '검색어', '%') OR
hp.birth LIKE CONCAT('%', '검색어', '%'));
개선 후 슬로우 쿼리
개선포인트1 OR 조건 분리
이름으로 조회 시 이름만 조건절에 추가합니다. 동일하게 번호로 검색할 경우 번호만 조건절에 추가되도록 변경하였습니다. 불필요한 생년월일 조건은 제거합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT DISTINCT hp.seq, hp.name, hp.hp_no, hp.patient_account_seq
FROM hospital_patient hp
WHERE
<trim prefixOverrides="AND | OR">
hp.hospital_seq = #{search.hospitalSeq}
<if test="search.nameKeyword != null and search.nameKeyword != ''">
AND hp.name LIKE CONCAT(#{search.nameKeyword},'%')
</if>
<if test="search.hpNoKeyword != null and search.hpNoKeyword != ''">
AND hp.hp_no LIKE CONCAT(#{search.hpNoKeyword},'%')
</if>
</trim>
개선포인트2 Like 인덱스 적용
Like 인덱스 처리는 %의 위치에 따라 동작이 다릅니다.
MySql에서 사용 중인 데이터 저장 구조는 B트리구조이기 때문에 작은값이 왼쪽부터 오른쪽으로 정렬됩니다. 즉 검색어 문자열 앞에 %를 붙이면 인덱스를 타지 않고, 뒤에만 %을 붙여야 옵티마이저가 인덱스를 활용할 수 있습니다.
다른 해결책으로는 전문 검색(FullText Search)를 사용하는 방법이 있습니다. 이번 개선에서는 전방일치(뒤에만 %를 붙이는 방식)을 사용하였습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT DISTINCT hp.seq, hp.name, hp.hp_no, hp.patient_account_seq
FROM hospital_patient hp
WHERE
<trim prefixOverrides="AND | OR">
hp.hospital_seq = #{search.hospitalSeq}
<if test="search.nameKeyword != null and search.nameKeyword != ''">
AND hp.name LIKE CONCAT(#{search.nameKeyword},'%')
</if>
<if test="search.hpNoKeyword != null and search.hpNoKeyword != ''">
AND hp.hp_no LIKE CONCAT(#{search.hpNoKeyword},'%')
</if>
</trim>
개선 결과
개선 전 실행 계획
1
hp.name like '%검색어%'

개선 후 실행 계획
1
hp.name LIKE '검색어%'
 옵티마이저 예측 레코드 건수는
옵티마이저 예측 레코드 건수는 159,954건에서 1건으로 줄일 수 있었습니다.
그러나 사용자가 원하는 검색어가 문자열 위치에 관계없이 검색이 되어야 하는 필요성이 있어 적용은 하지 못하였습니다.
세 번째 슬로우 쿼리
개선 전 슬로우 쿼리
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
SELECT *
FROM (SELECT 필요 컬럼들
FROM favorites fa
LEFT JOIN hospital ho ON ho.seq = fa.hospital_seq
LEFT JOIN hospital_op_time thot ON thot.hospital_seq = ho.seq AND (SELECT CASE DAYOFWEEK(NOW())
WHEN '1' THEN '일요일'
WHEN '2' THEN '월요일'
WHEN '3' THEN '화요일'
WHEN '4' THEN '수요일'
WHEN '5' THEN '목요일'
WHEN '6' THEN '금요일'
WHEN '7'
THEN '토요일' END) = thot.label
(... 필요 조인)
WHERE fa.del_yn = 'N'
GROUP BY ho.seq) AS favorite_hospital
ORDER BY favorite_update_dtm DESC;
즐겨 찾는 병원을 최신 순으로 조회하는 쿼리입니다.
개선 후 슬로우 쿼리
개선 전 쿼리의 실행 계획을 확인했을 때 select_type이 DERIVED로 나타났습니다.

DERIVED는 단위 select 쿼리의 실행 결과로 메모리 또는 디스크에 임시 테이블을 생성하는 것을 뜻합니다.
MySQL 서버는 조인 쿼리에 대해 최적화가 이루어졌고, 가능하면 derived 형태는 join으로 변경하는 것이 성능상 이점이 있습니다(참고 : RealMySQL 8.0)
즉, 개선을 위해 서브 쿼리를 join을 사용하는 형태로 변경합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
SELECT ho.*
FROM (SELECT 필요 컬럼들
FROM favorites fa
LEFT JOIN hospital ho ON ho.seq = fa.hospital_seq
LEFT JOIN hospital_op_time thot ON thot.hospital_seq = ho.seq AND (SELECT CASE DAYOFWEEK(NOW())
WHEN '1' THEN '일요일'
WHEN '2' THEN '월요일'
WHEN '3' THEN '화요일'
WHEN '4' THEN '수요일'
WHEN '5' THEN '목요일'
WHEN '6' THEN '금요일'
WHEN '7'
THEN '토요일' END) = thot.label
(... 필요 조인)
WHERE fa.del_yn = 'N'
GROUP BY ho.seq
ORDER BY MAX(fa.update_dtm) DESC;
개선 결과
개선 전 실행 계획

개선 후 실행 계획

select_type이 derived에서 simple 로 변경되었습니다.
옵티마이저 예측 레코드 건수를 11,242건 이상에서 대략 400 건으로 줄일 수 있었습니다.
느낀 점
프로젝트의 변경 범위가 넓고 일정이 길지 않기 때문에, SQL 마이그레이션 중 성능 개선에 충분히 주의를 기울이지 못했습니다.
아직 개선이 필요한 쿼리들이 많기 때문에 데이터베이스의 옵티마이저, 인덱스, 실행 계획에 대해 더 깊이 공부 하면서 사용자가 더 쾌적하게 서비스를 이용할 수 있도록 개선해 나갈 예정입니다.